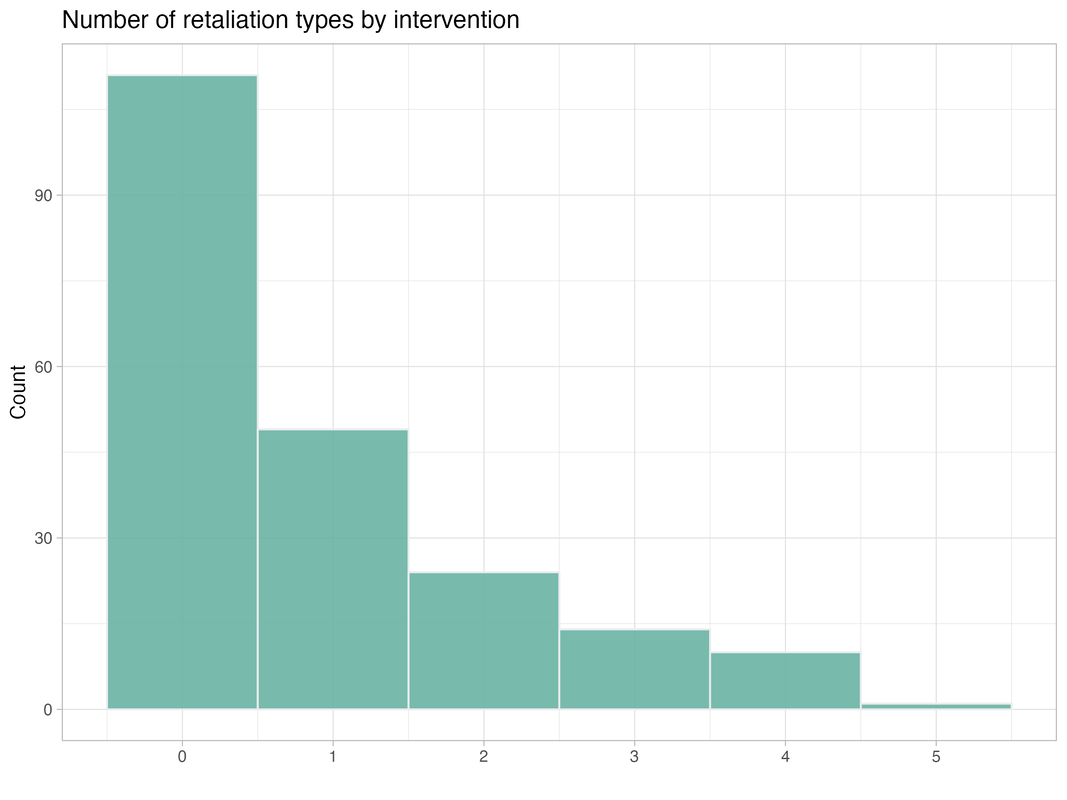
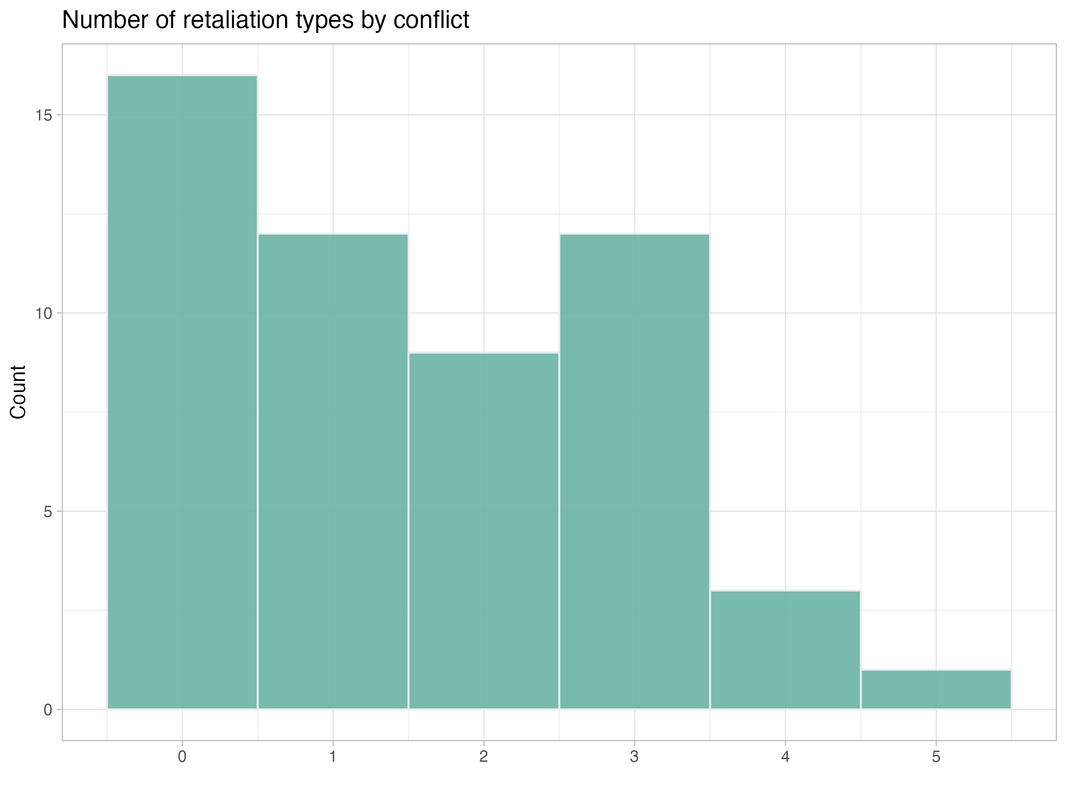
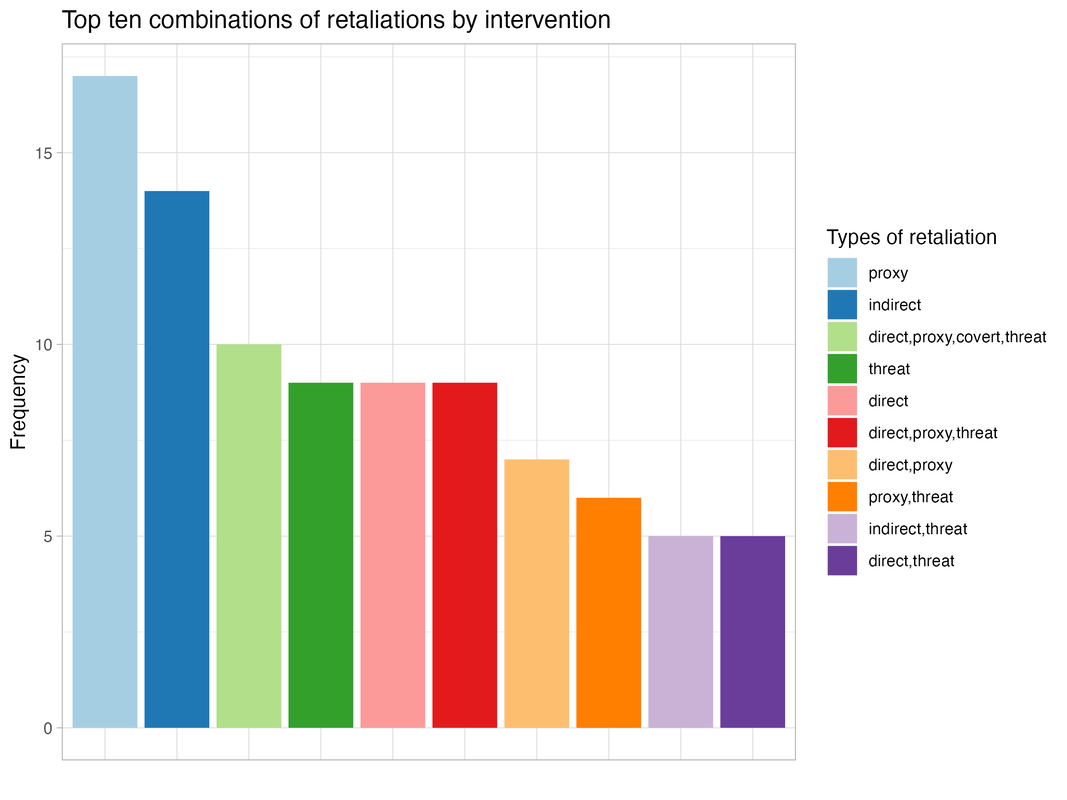
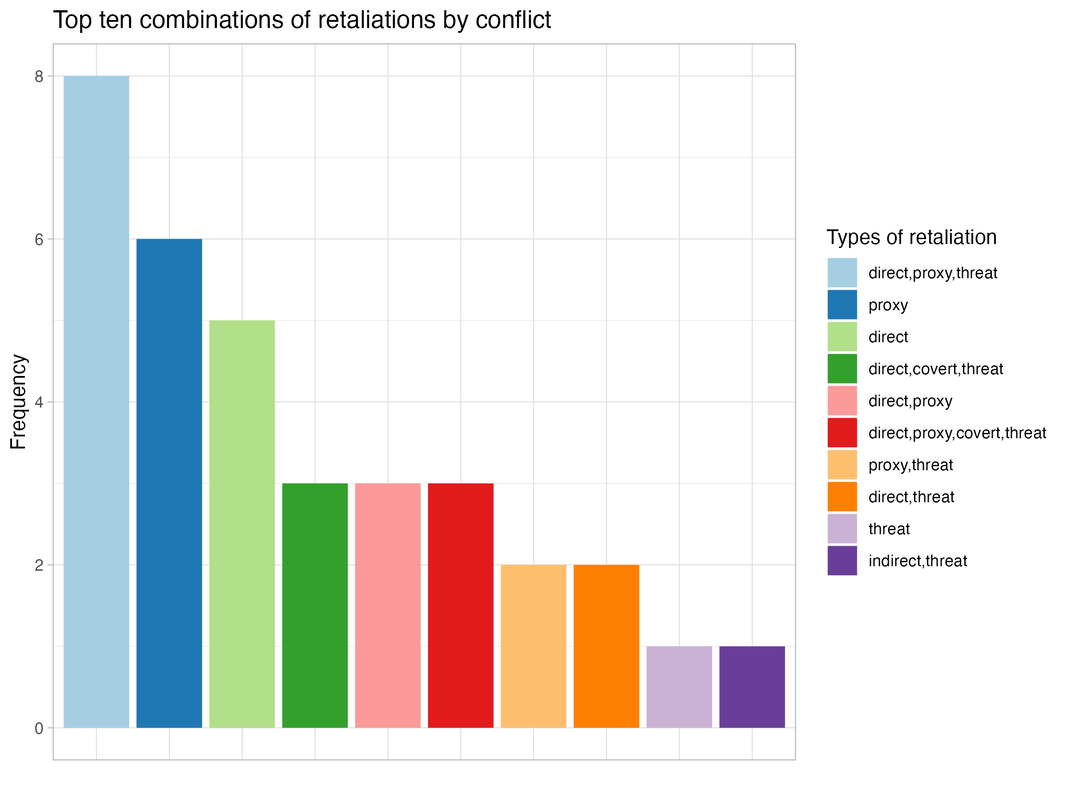
Predicting civil war interventions
In an ongoing project, I am building a predictive model of interventions into civil war by third-party states. I am using the UCDP External Support Dataset, which captures interventions at a high degree of granularity, to generate a categorical outcome at the civil war-potential intervener level: no intervention, government support, and rebel support. I include every other state in the system as a potential intervener in a civil war, yielding a total of 34,552 dyadic observations.
There are several challenges in building such a predictive model. First, because most countries do not intervene in a given civil war (even if most civil wars do experience some form of intervention), the outcome variable has a severe class imbalance problem. There are 872 government-sided interventions, 256 rebel-sided interventions, and 33,432 observations with no intervention in the dataset. Second, there are no existing predictive models of civil war intervention that I am aware of, so there is little guidance in the literature about which machine-learning techniques to use or which features are more or less important. I therefore take an iterative and exploratory approach to model building (you can find all the code for this project in my Github repo).
There are several challenges in building such a predictive model. First, because most countries do not intervene in a given civil war (even if most civil wars do experience some form of intervention), the outcome variable has a severe class imbalance problem. There are 872 government-sided interventions, 256 rebel-sided interventions, and 33,432 observations with no intervention in the dataset. Second, there are no existing predictive models of civil war intervention that I am aware of, so there is little guidance in the literature about which machine-learning techniques to use or which features are more or less important. I therefore take an iterative and exploratory approach to model building (you can find all the code for this project in my Github repo).
|
|
I start by estimating several inferential models using multinomial logistic regression to identify an appropriate benchmark model. Then, I use Box’s loop approach to iteratively build a set of predictive models using different algorithms suited to multiclass models, including a wide range of features. I use cross validation to tune hyperparameters and evaluate and compare model performance, and after each iteration I use a range of diagnostic tools and domain expertise to optimize the models.
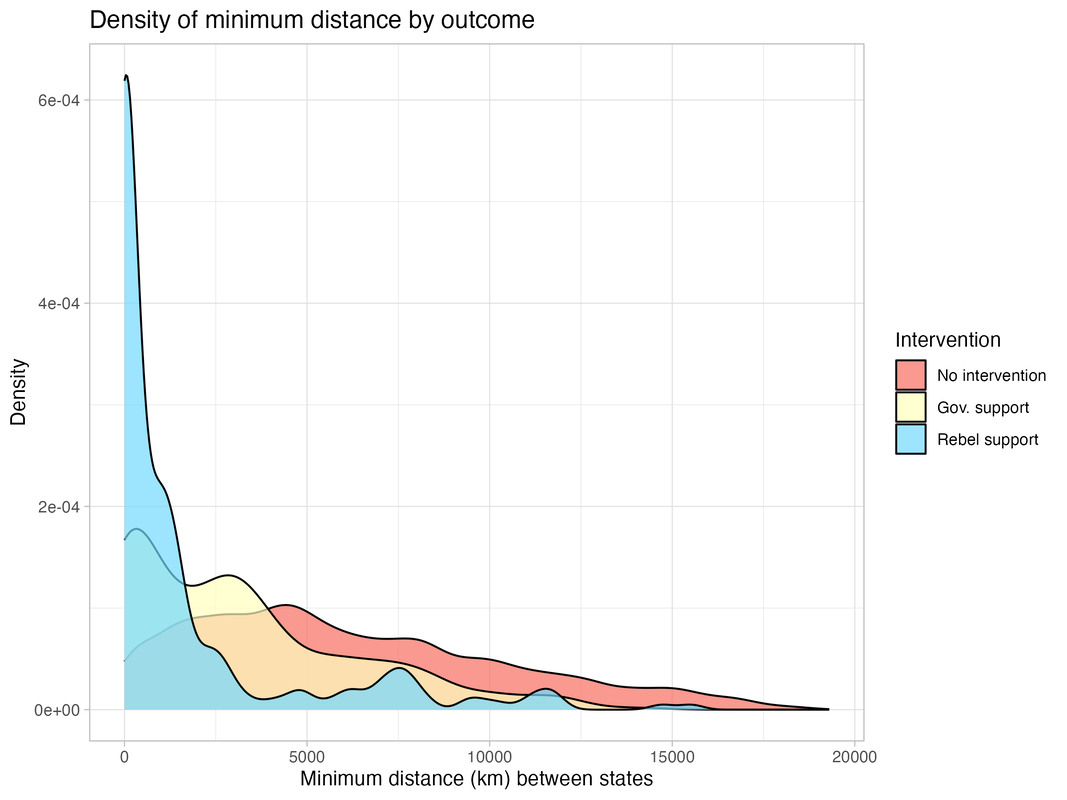
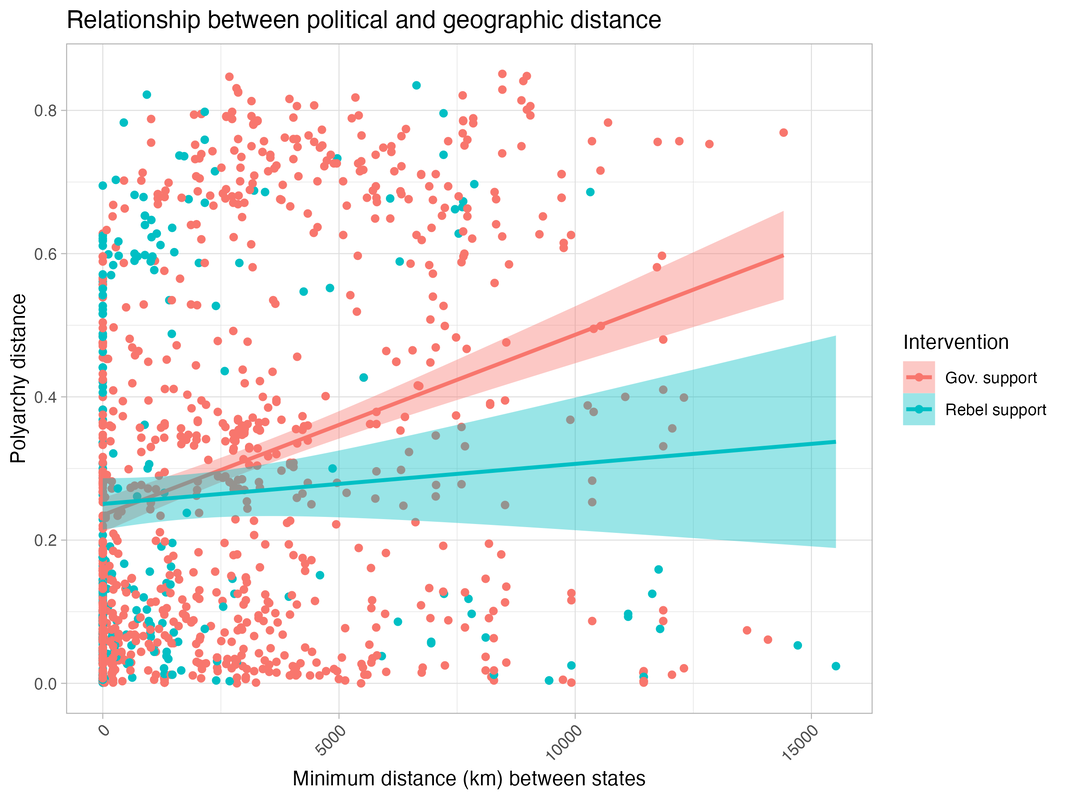
To build a benchmark model, I first construct novel predictors of intervention. While existing studies highlight numerous factors that influence the decision to intervene (e.g., co-ethnic ties), most are context-specific features. In general, intervention should depend on the political preferences of the third party, and so whether it decides to intervene and on which side is a function of how far apart the two states are. The further apart the two states are, the more likely the third party is to intervene on the side of the rebels instead of the government, and vice-versa.
To build a benchmark model, I first construct novel predictors of intervention. While existing studies highlight numerous factors that influence the decision to intervene (e.g., co-ethnic ties), most are context-specific features. In general, intervention should depend on the political preferences of the third party, and so whether it decides to intervene and on which side is a function of how far apart the two states are. The further apart the two states are, the more likely the third party is to intervene on the side of the rebels instead of the government, and vice-versa.
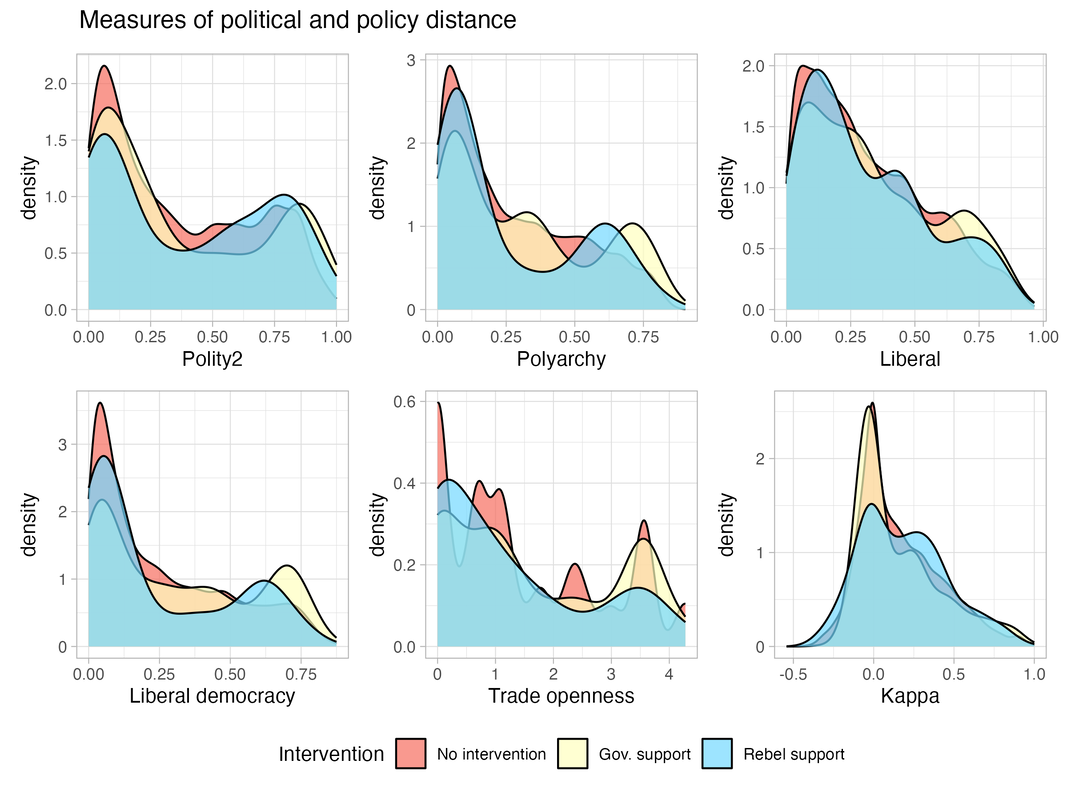
I construct a set of variables of political or policy distance by using different unit-level variables as inputs to generate the absolute difference between the two states’ score (input variable in parenthesis):
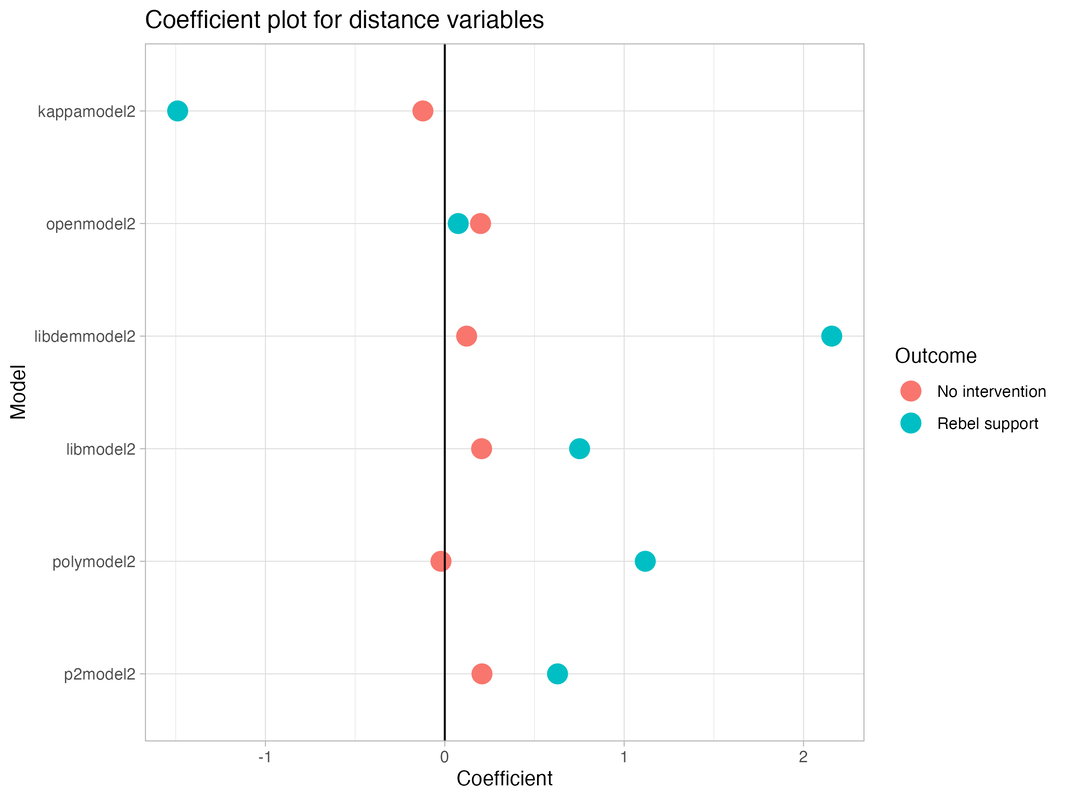
I estimate a set of models (with similar sets of covariates) using multinomial logit and compare their performance. I pick the Liberal Democracy model because it performs the best according to the Akaif-Information Criteria and its results fit my theoretical expectations.
- P2dist (Polity2) measures the difference in states’ level of democratization.
- Polydist (Polyarchy index from V-Dem) measures the difference in electoral democracy achieved in the two states.
- Libdist (Liberal index from V-Dem) captures the difference in liberal ideology in the two states.
- Libdemdist (Liberal democracy index from V-Dem) combines polyarchy and liberal measures to capture the difference in the level of liberal democracy achieved in the two states.
- Opendist (Trade openness from the Chinn-Ito index of financial openness) captures the difference in the states’ integration in the world economy.
- Kappavv is an existing dyadic measure of the two states’ foreign policy similarity, based on observed dissimilarity of ties while accounting for the distribution of foreign policy ties in the system and individual states’ propensity to form ties (Hage 2011).
I estimate a set of models (with similar sets of covariates) using multinomial logit and compare their performance. I pick the Liberal Democracy model because it performs the best according to the Akaif-Information Criteria and its results fit my theoretical expectations.
I take an iterative approach to building the predictive model. I start out with a broad set of features and perform pre-processing (including train-test split, normalization, and knn-imputation for missing data), before using recursive feature elimination to assess whether any features are unnecessary. Once that is done, I move on to the Box’s loop approach.
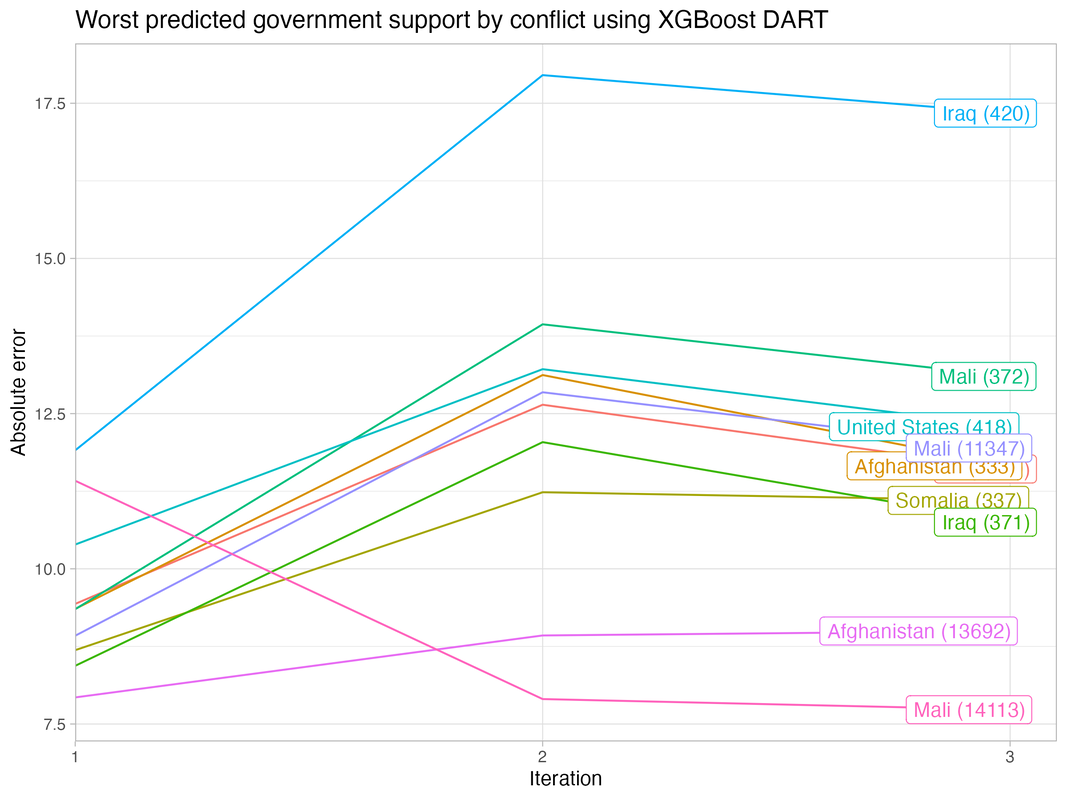
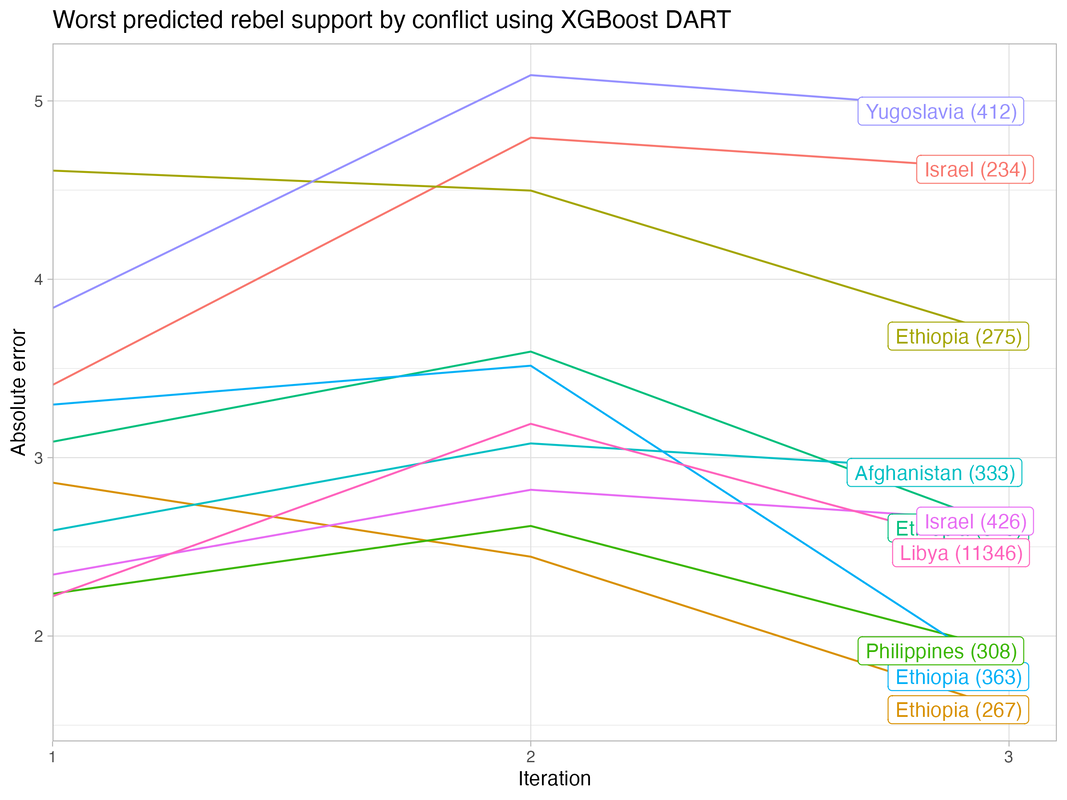
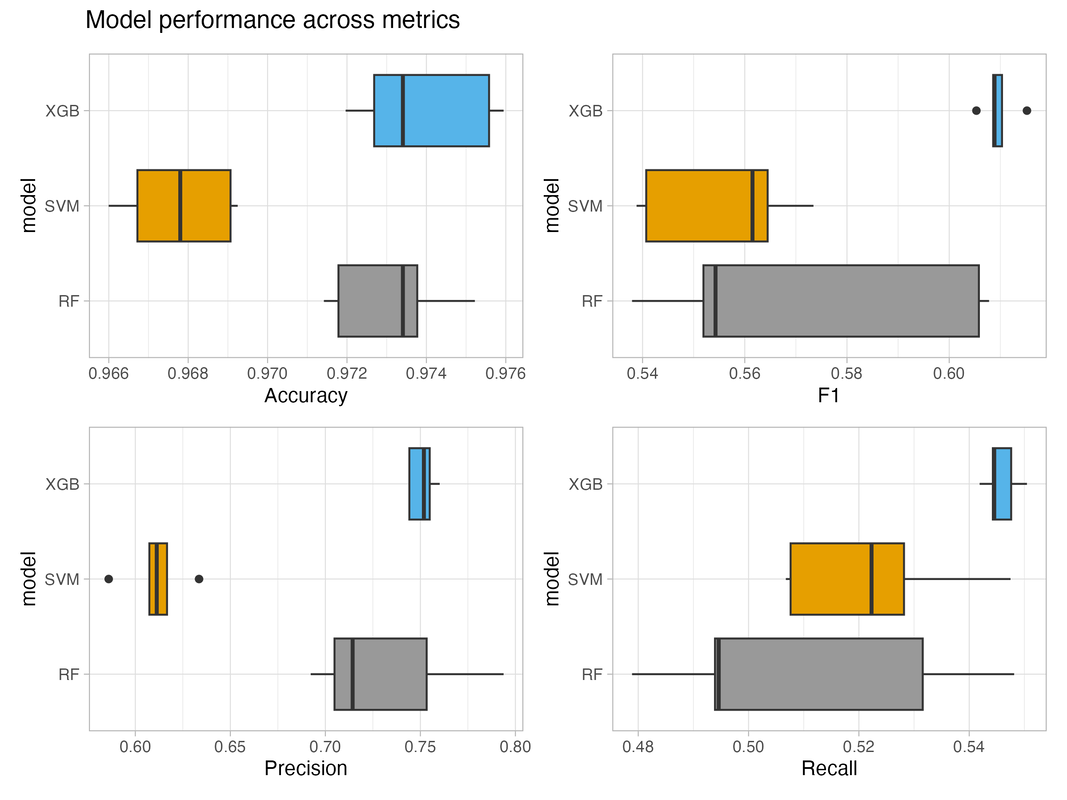
For each iteration, I tune and train three separate models using random forest, support vector machine, and XGBoost DART algorithms using five-fold cross validation. I compare their performances based on the F1 metric, and then use diagnostic tools (see below) to assess commonalities across cases where the models perform poorly. After evaluating the models, I move on to the next iteration to optimize them. I use my domain expertise to identify additional features, performance metrics to re-tune hyperparameters, and other tools (e.g., elastic net estimation) to eliminate unimportant features.
For each iteration, I tune and train three separate models using random forest, support vector machine, and XGBoost DART algorithms using five-fold cross validation. I compare their performances based on the F1 metric, and then use diagnostic tools (see below) to assess commonalities across cases where the models perform poorly. After evaluating the models, I move on to the next iteration to optimize them. I use my domain expertise to identify additional features, performance metrics to re-tune hyperparameters, and other tools (e.g., elastic net estimation) to eliminate unimportant features.
|
|
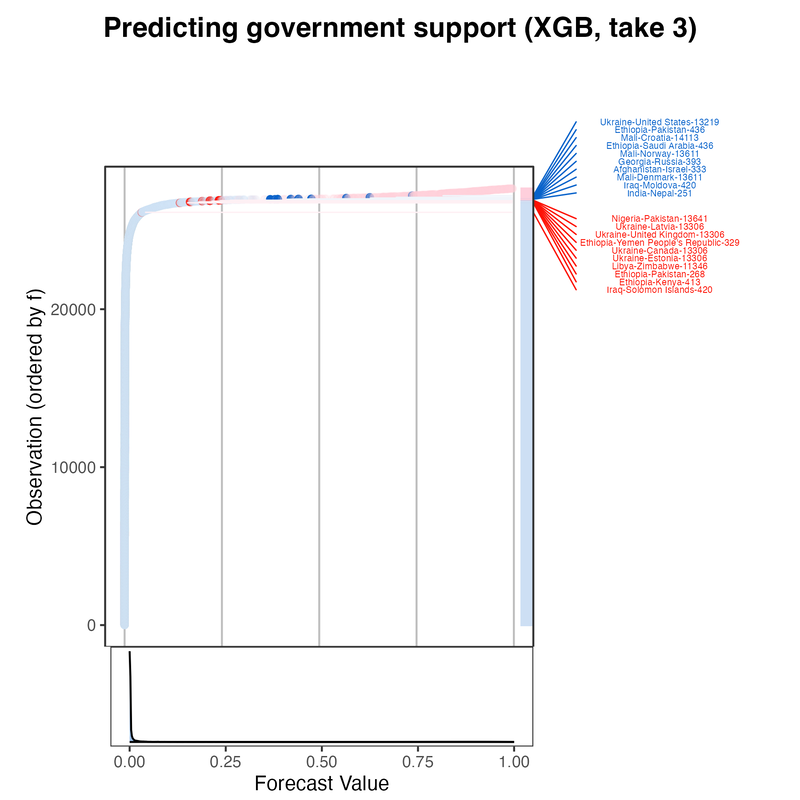
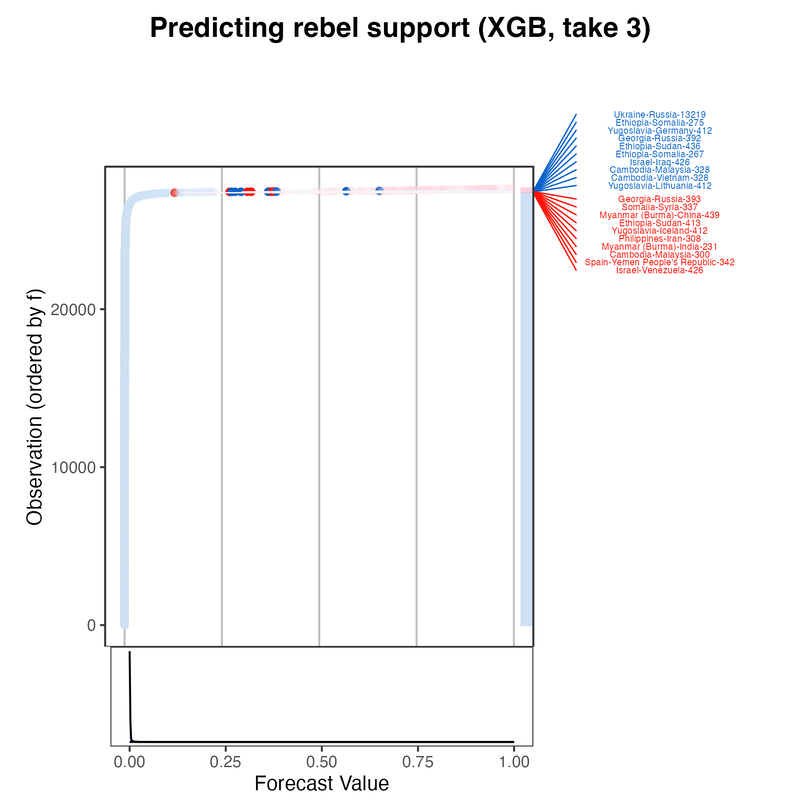
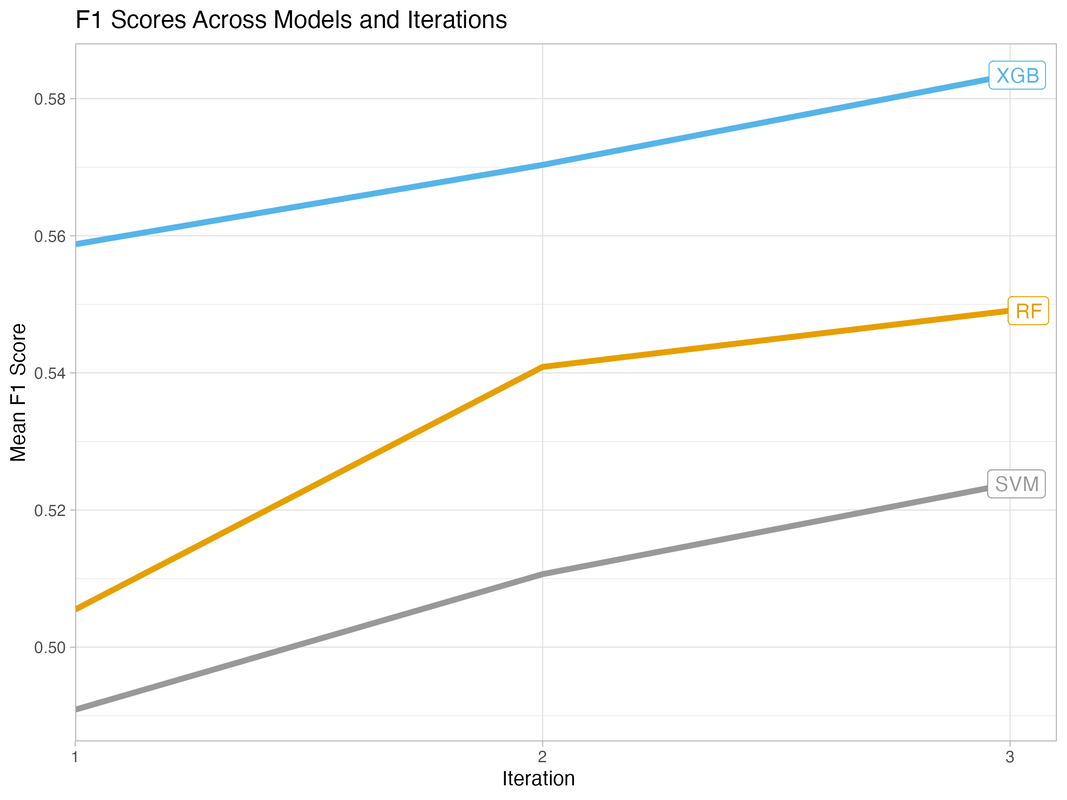
All versions of the machine learning model perform significantly better than the benchmark model (Mean F1 score of 0.37), and model performance improves across iterations (see below). The XGBoost DART model outperforms the random forest and support vector machine models on the key performance metric, and its performance is more stable.
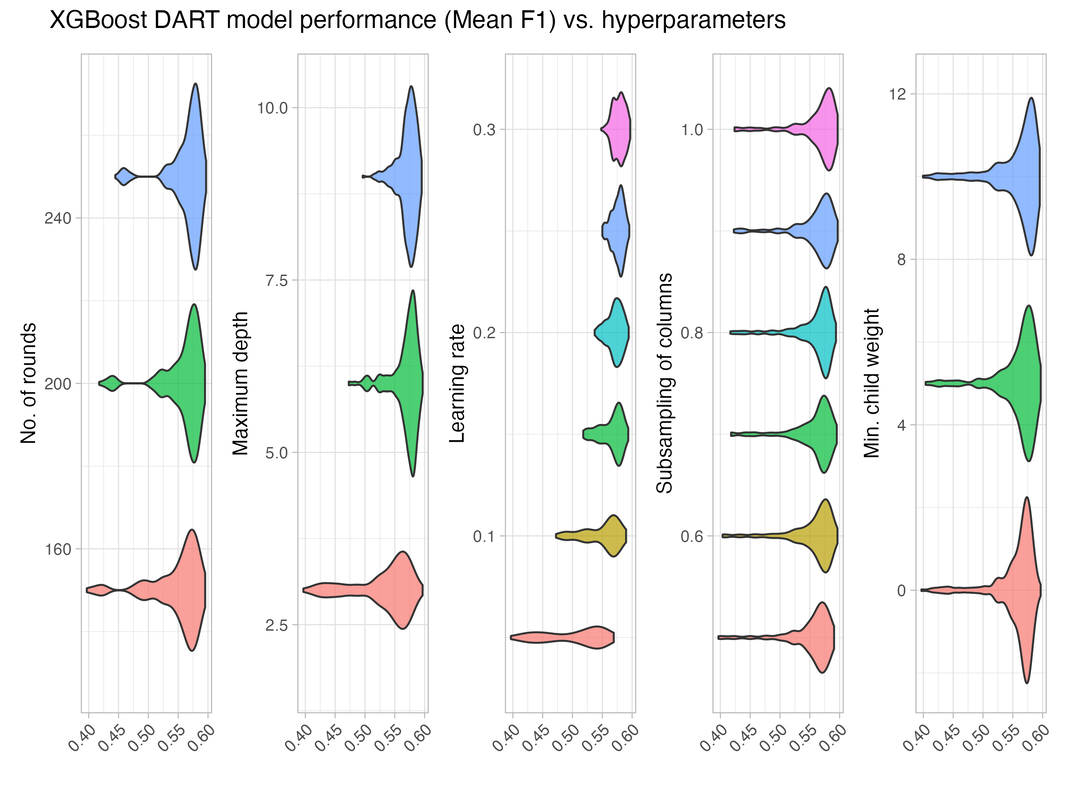
Tuning XGBoost DART models can be challenging because of the number of hyperparameters, so I plot average model performance across hyperparameter values to assess how sensitive the model is. The below plot shows that model performance varies substantially by maximum depth of tree and learning rate.
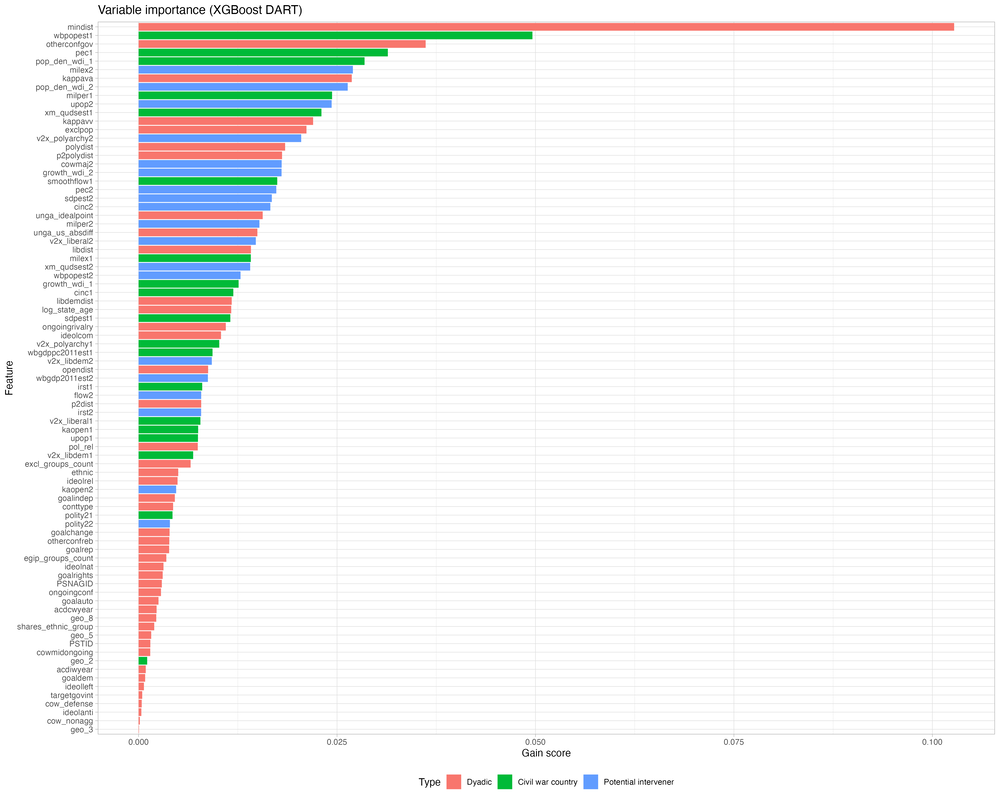
The predictive models offer insights into which features matter for civil war interventions. As the variable importance plots below show, a lot of variables matter, making the models complex. The geographic distance between states (mindist) is by far the most important predictor of intervention, followed by other dyadic and monadic indicators such as the population size in the civil war country (wbpopest1), whether the third party is already supporting the government in another civil war (otherconfgov), and the two states’ foreign policy similarity (kappavv).